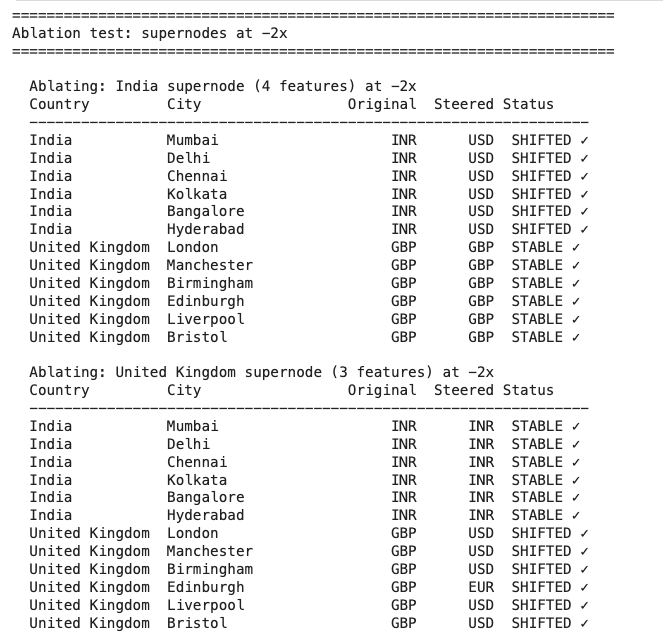
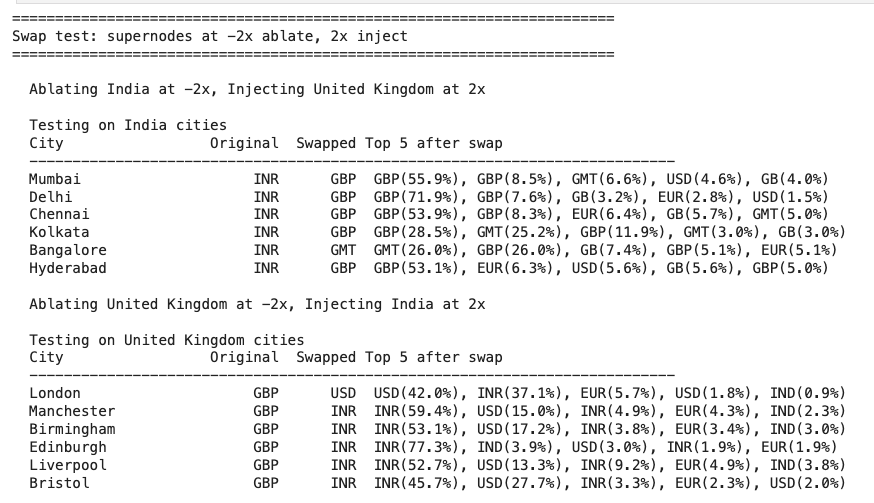
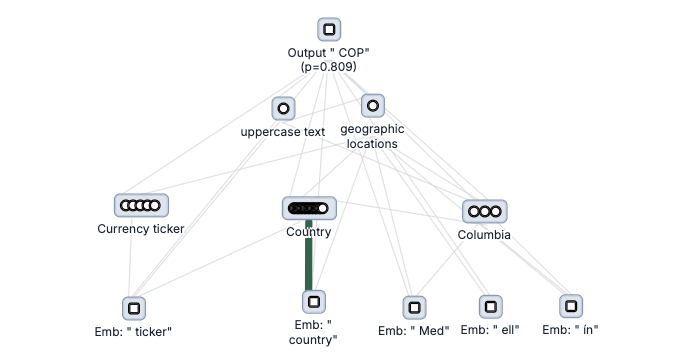
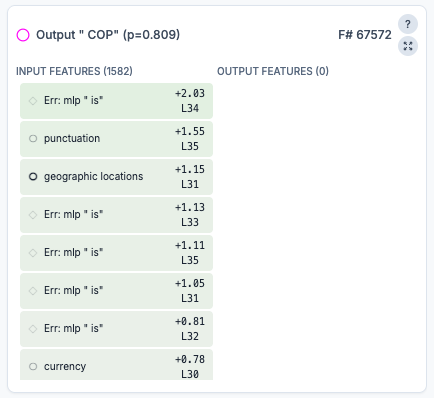
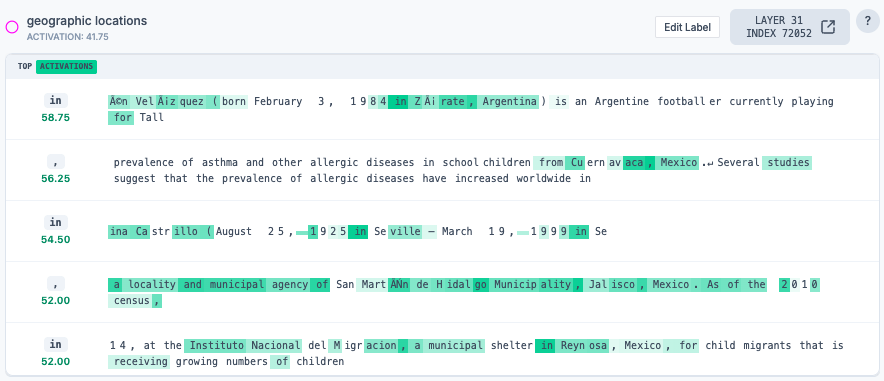
How do LLMs perform list indexing? Namely, how do they complete prompts like:
>>> nums = [2,8,1,9,7,4]
>>> nums[4]
Intuitively, models must compute the correct answer (7) somewhere, perhaps in a particular layer and token position. We can try and identify that point with linear probes.
Linear probes essentially tell us whether some piece of information is present in a models residual stream. If a linear probe is robustly able to recover some piece of information, it is as though that information is a “variable” in the model’s working memory, ready to be used at later steps.
To start investigating this, I generated a dataset of prompts with randomized lists of length 6 and randomized indices, formatted as Python code:
Dataset size: 600
Samples per position: 100
Example prompts:
'>>> nums = [4,3,3,7,0,0]\n>>> nums[2]\n'
→ position=2, target=3
'>>> nums = [4,0,2,3,2,3]\n>>> nums[1]\n'
→ position=1, target=0
'>>> nums = [4,9,5,1,6,5]\n>>> nums[5]\n'
→ position=5, target=5
The model gemma-3-4b-pt is able to reliably perform this task, predicting the correct value with 97% accuracy:
Overall accuracy: 97.0% (194/200)
Accuracy by queried position:
Position 0: 100.0% (31/31)
Position 1: 100.0% (39/39)
Position 2: 100.0% (32/32)
Position 3: 93.8% (30/32)
Position 4: 97.5% (39/40)
Position 5: 88.5% (23/26)
This is impressive; there are 10^6 possible lists, so the model is probably doing something more sophisticated than memorising every possible answer. Note its accuracy decreases slightly in the later positions, although not by much.
Handily, the Gemma 3 tokenizer individually tokenizes each digit in the prompt, so it will be easy to compare the model’s behaviour on particular indices in the list:
Token breakdown:
pos 0: 2 → '<bos>'
pos 1: 22539 → '>>>'
pos 2: 27536 → ' nums'
pos 3: 578 → ' ='
pos 4: 870 → ' ['
pos 5: 236771 → '0'
pos 6: 236764 → ','
pos 7: 236800 → '3'
pos 8: 236764 → ','
pos 9: 236800 → '3'
pos 10: 236764 → ','
pos 11: 236770 → '1'
pos 12: 236764 → ','
pos 13: 236812 → '4'
pos 14: 236764 → ','
pos 15: 236825 → '6'
pos 16: 236842 → ']'
pos 17: 107 → '\n'
pos 18: 22539 → '>>>'
pos 19: 27536 → ' nums'
pos 20: 236840 → '['
pos 21: 236778 → '2'
pos 22: 236842 → ']'
pos 23: 107 → '\n'
Total tokens: 24
Now, we can start probing. We will focus on probing the last token position ('\n'), because it has the full context through attention. In theory, the residual stream at that position may encode all of the information that the model has derived from the prompt - the elements in the list, and eventually the value of the target index (ie. nums[i]). It is very possible that this information can be recovered from other token positions however, at even earlier layers.
To motivate the use of linear probes, it is worth pondering how the model might encode all of this information into a single residual stream. One obvious hypothesis would be that is has index-specific digit directions, ie. there is a direction for “index 0 is 4,” a separate direction for “index 1 is a 4”, and so on. With only 10 digits × 6 positions = 60 directions, this seems feasible. In any case, as long the model is using linear representations, then linear probes will find the best projection to extract it.
We will first try to answer a basic question - can each element of the list be recovered from the residual stream of the final token position? If every element is present in the residual stream at all times, it becomes more nuanced to identify when the model has isolated the target element. Our ultimate goal will be to detect if the correct answer is more recoverable than the other elements.
To establish this baseline, we first train “per-index” probes for each layer. Specifically, given only the model’s activations for a single layer, the probe outputs a label from 0-9 predicting the value of the list at its index:

Despite only having access to the models activations, the probes can learn how the model encodes information and reliably extract the value of each index. If the model does not linearly represent an element in the residual stream, then the corresponding probe will not have enough signal to achieve high accuracy. In that case the probe has a 1 in 10 chance of guessing the correct answer.
With lists of length 6 and 35 layers, there are 210 per-index probes; luckily they are cheap to train. We use our dataset to sample residual stream activations for each layer, then fit linear probes to the data with a sklearn LogisticRegression.
We can then plot the per-layer accuracy for each index:
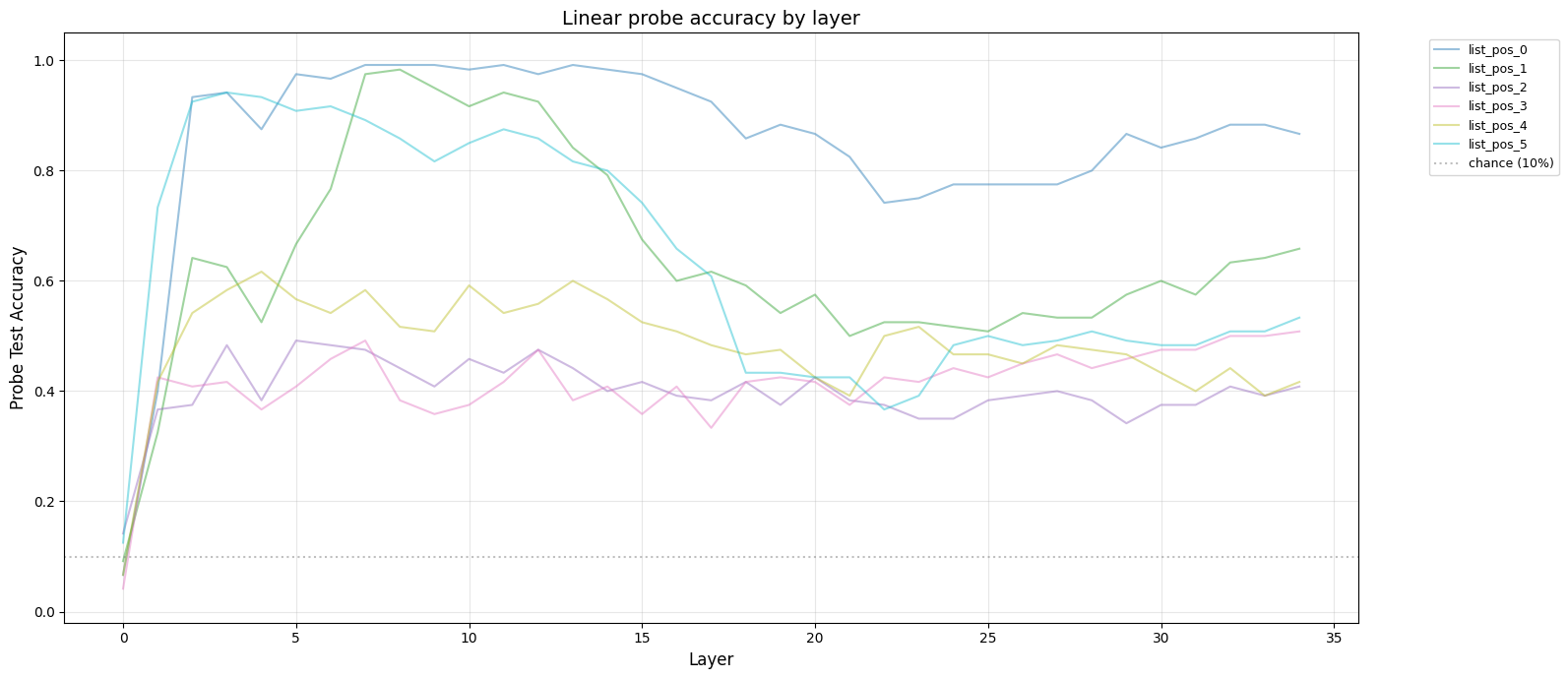
The family of probes for a given index is represented by a coloured line. Each datapoint indicates how successful a probe is at recovering its list element at that layer. For example, the probe for index 1, layer 16 has an accuracy of 60%; the value of the 2nd element in the list can reliably be recovered from the residual stream at layer 16.
There are a few trends. None of the elements fall below the chance line of 10%; they are all always present in the residual stream. The model does indeed move information about each element to the final token position.
The value of 1st element in the list is always prominent in the residual stream, never dipping below 70% accuracy. This element might be treated specially by the model; arr[0] is a common pattern. The 2nd and 6th values are initially amplified, but gradually decrease between layers 13 and 20. The remaining elements hover around the 35-60% range.
With this established, we can now try and identify when the model isolates the target digit. That is, out of all the elements present in the residual stream, which is the “correct” one to output based on nums[i]? To do this, we train a “target probe” for each layer that, given an activation, learns to output the value of the list at the target index:

With these probes trained, we can overlay their accuracy onto the per-index diagram:
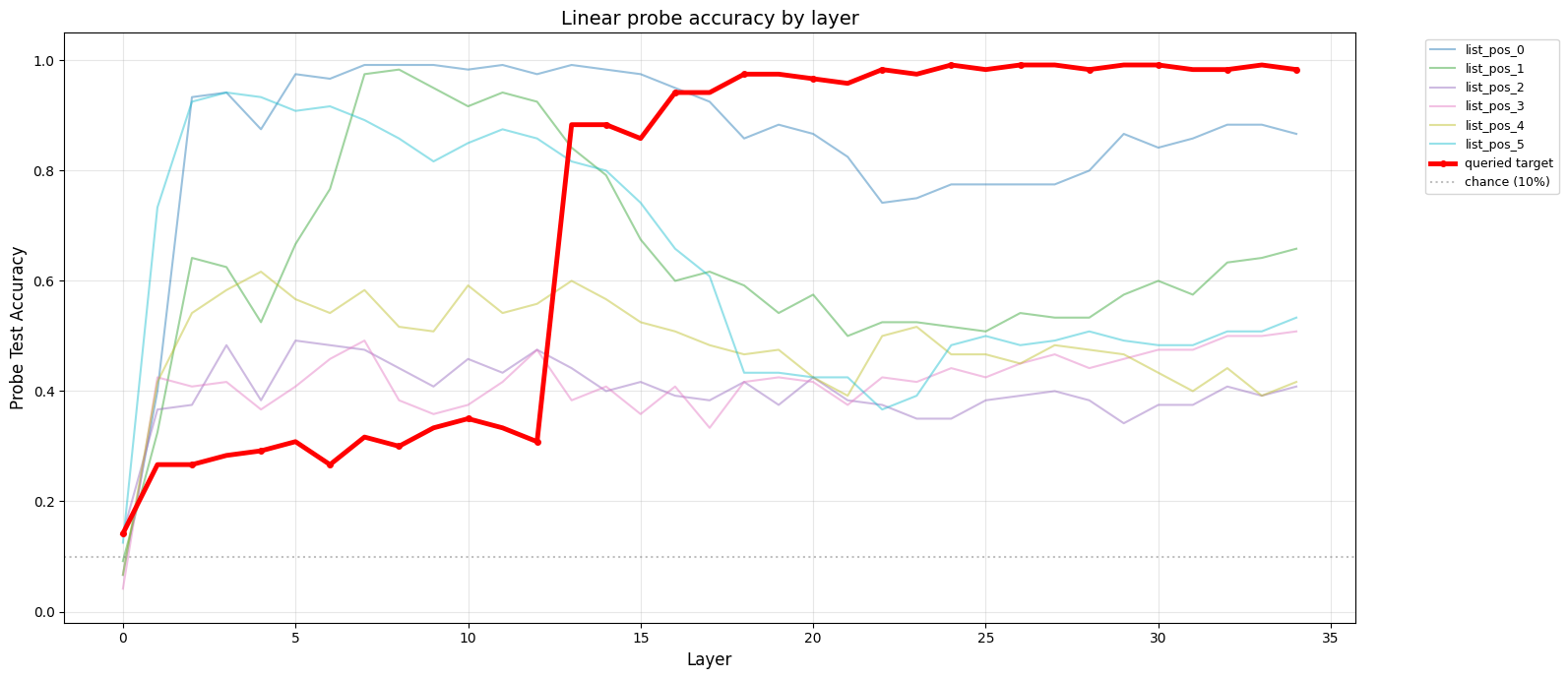
We see a clear trend - an almost inverse relationship between the linear recoverability of the target digit and the other elements. At layer 13, the accuracy of the target digit shoots from 30% to 85%, and asymptotes to nearly 100% in the subsequent layers; meanwhile the accuracy of the other digits gradually levels off.
To answer our initial question, it would appear that the model identifies the correct answer on or before layer 13. The correct answer is amplified heavily, and the model starts “ignoring” the other elements, which are slowly overwritten in the residual stream.
Of course, while this graph offers a intriguing picture, there are a few caveats to this approach. High probe accuracy also does not imply that the model uses that information causally - it may be a byproduct of the computation rather than an input to it. Verifying this would require causal interventions like activation patching. In addition, we only probed the final token position; the model may perform key computations at other positions earlier in the forward pass.
More investigation is needed…
]]>