How does Qwen3-4B recall currencies?
After spending the last year designing tasks that are hard for AI, I have become interested in the question of how LLMs think, specifically how they are able to solve novel problems.
To start to answer this question, I looked to the obvious place - Mechanistic Interpretability. A key idea there is circuit tracing, that models have “features” which are used in “circuits” to predict the output.
As a first go, I investigated how a model answers a very much not novel prompt:
Fact: the currency ticker of the country containing Medellín is
When Qwen3-4B completes this prompt, it correctly answers “COP”. But not only that - it has internal representations of currencies, countries, Colombia, The Americas, and more!
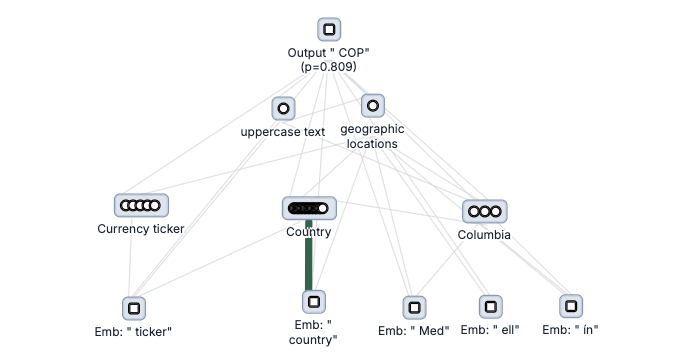
If you are curious about this graph, read on.
Circuit tracing
I followed the circuit tracing approach outlined by Anthropic here. In brief, they train a “replacement model” which approximates the output of an LLM, but with more interpretable components.
The tool I used is the Neuronpedia Circuit Tracer. For the unfamiliar, this tutorial gives a good introduction to the application and circuits in general.
The basic hypothesis of circuits is intuitive; models are probably learning various concepts and synthesising them in learned algorithms. If we can identify these features, we can see when they activate and what happens when they are ablated.
Choosing the prompt
I wanted a prompt that requires multi-step reasoning but has an unambiguous answer. I chose the following:
Fact: the currency ticker of the country containing Medellín is
To complete this prompt, the model must recall a) which country Medellin is in, and b) its currency ticker. Hopefully, this reasoning chain is reflected as a circuit in the model. This format is common in circuit tracing, so I was confident it would work.
The model correctly predicts “COP” with 81% probability.
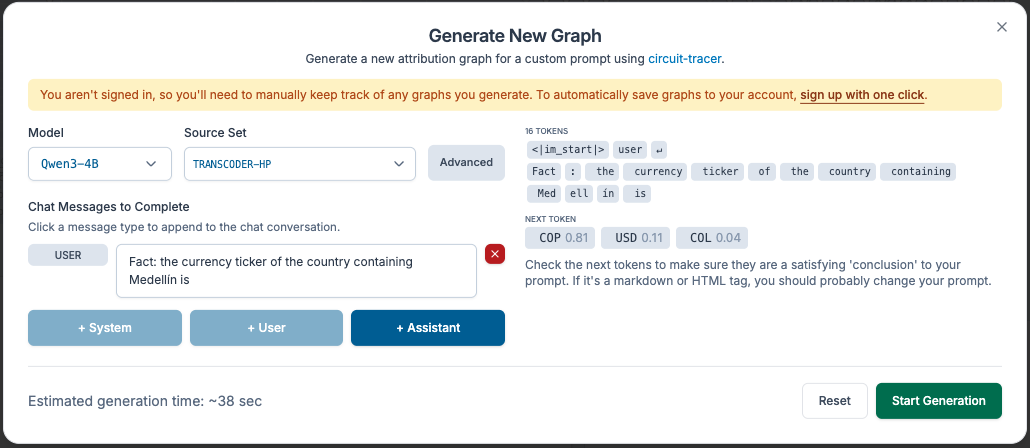
I chose Qwen3-4B because it was the biggest model with steering (i.e. ablating features).
As for the formatting, the “Fact:” prefix just promotes a succinct response from the model. Also, Qwen3-4B is instruction-tuned, so the full prompt follows a user/assistant format. Conceptually the model is predicting the next token that a user would say.
Features
With the setup complete, Neuronpedia generates an attribution graph for the prompt.
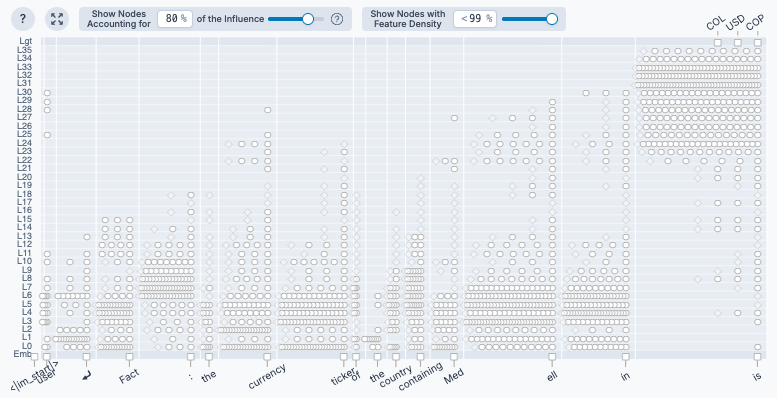
That’s a lot! The input tokens run along the bottom, and the next token predictions are at the top right. The features take up the middle, separated by layer.
A useful heuristic is to try to identify two types of features:
Input features tend to appear in earlier layers and activate on particular input tokens. They are like the “source” of some information flowing through the network.
Output features tend to activate in later layers. They activate in response to input features and influence the next token that the model will predict. For this reason they are often denoted by “say X”.
For example, take the prompt:
The national dish of Italy is
Imagine that a “food” input feature activates on the token “dish”. If this is ablated, the model will kind of forget that the question is about food, and give another answer, like the national animal.
Suppose also that there is a “say a food” output feature. If this is ablated, the model will not immediately say the answer, but give an indirect completion like “…is called pizza”. It does not forget the question (the “food” feature is still present), but its response is temporarily suppressed.
In practice, each feature is an input and output to many others, but this heuristic gets us quite far.
Input features
We can find input features by inspecting the features activated by each token in the prompt. Handily, Neuronpedia provides automated labels for features based on their activations.
Here are a few that I found.
The “Colombia” feature
Starting with the “in” token (i.e. Medellín), there are a number of features activated at this position that reference Colombia.
Interestingly, these features (in pink) appear in the middle layers of the network. Perhaps it takes a few layers for attention to mix the three tokens of “Med/ell/ín” into a single concept.
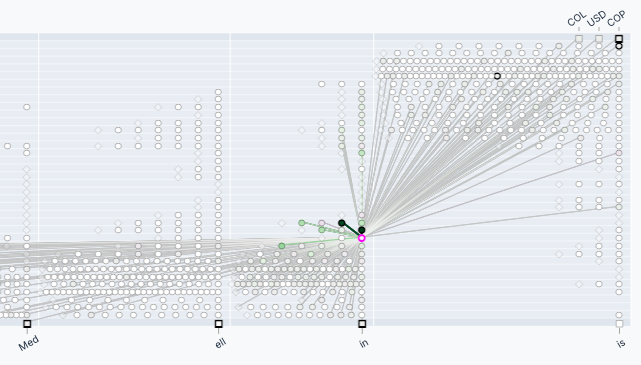
Looking at their top activations, these features activate on places and concepts related to Colombia.
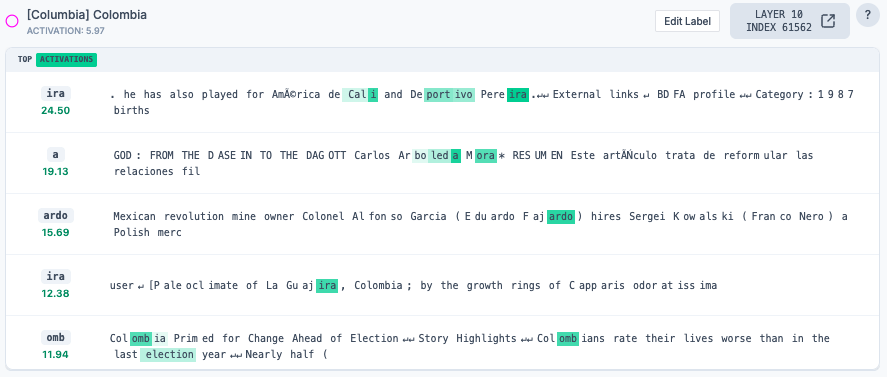
If all these features are ablated, the model outputs “MXN”!

There is clearly still Latin American influence in the answer. Well, if the “Americas” feature is also ablated, the model outputs “ZM” (Zambia)!

The “country” feature
Looking at the token “country”, there are a number of features labelled “country”, “nation”, etc.
If these are ablated, the model answers “USD”. This intervention probably discourages the model from answering for a specific country, so it just outputs a generic currency.

The “currency ticker” feature
For the token “ticker”, there are various features labelled “currency”, “codes”, etc.
As would be expected, these activate on financial terms and codes.
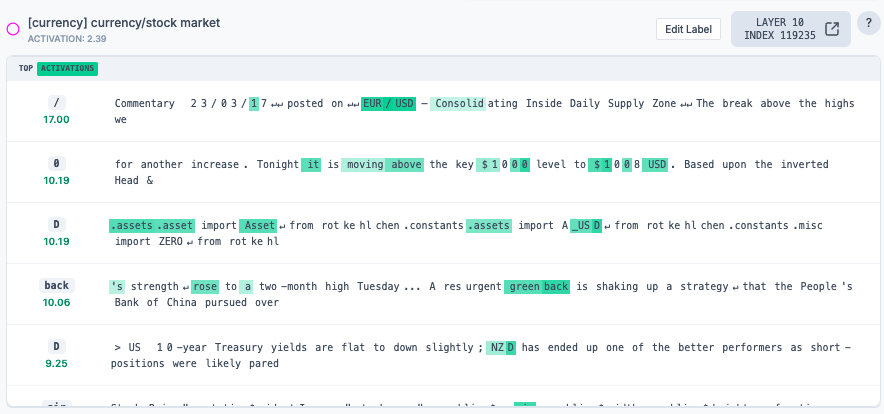
If these features are ablated, the model gives a strange completion counting to 9. I’m not sure how to interpret this, but this feature is clearly important to the output.

Output features
To find output features, we can see which features influenced the model’s prediction.
These are more difficult to interpret as there is no dedicated “say COP” feature. Also, a number of the activations for this prompt come from error nodes, which means there was a mismatch between the replacement model’s output and the underlying model; a feature cannot be attributed to the output.
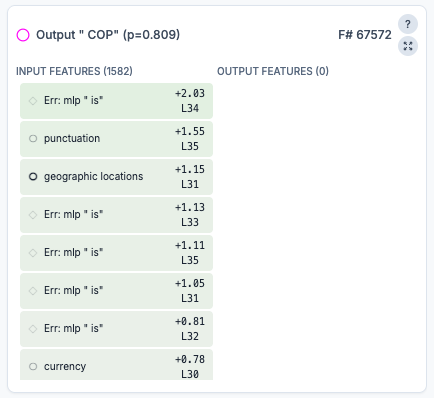
The “say uppercase text” feature
Looking at the “COP” prediction, one of the top inputs is an “uppercase text” feature which activates on capital letters.

In ablating this feature, the model gives a longer answer starting with “Colombian pesos”.
This feature probably makes the model output a ticker specifically, instead of the full name of the currency. By intervening, we essentially force the model to reach the answer in an indirect way.

The “say a geographic location” feature
Another top feature is labelled “geographic locations”. It activates mostly when completing Latin American place names.
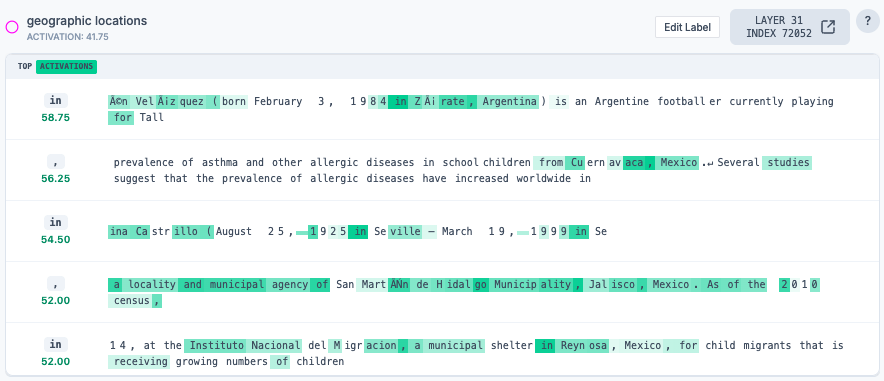
If this is ablated, the completion is “USD”. It seems that this feature, perhaps working in concert with others, influences the model to answer about Colombia specifically.

The attribution graph
Now we have the important features, they can be visualised in a subgraph.
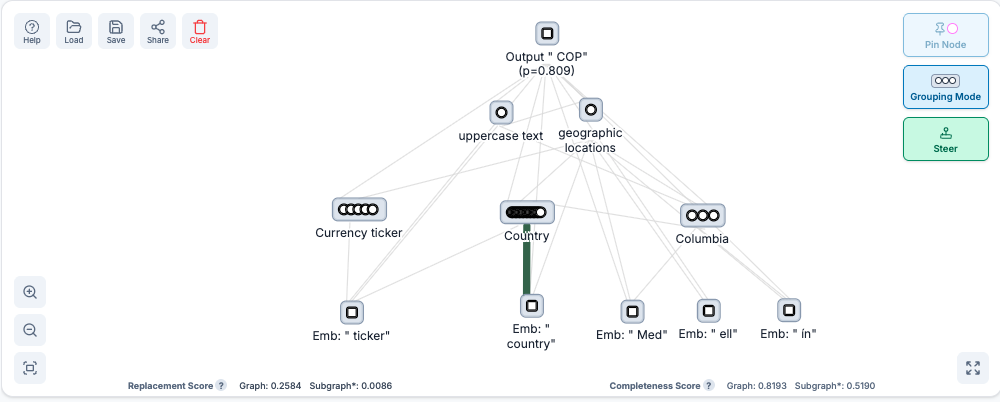
So, how does this model complete this prompt?
My interpretation is that the prompt activates features for specific countries (i.e. Colombia), and the concepts of currency tickers and countries in general. These then activate output features which separately make the model say a) the currency of a specific country and b) to format it as a ticker.
Of course, this is not a rigorous analysis. There are likely many more features that play a role, and it is unclear exactly how they interact.
You can also try changing elements of the prompt. For example, in changing the city name to “Cartagena”, I found many of the same features were activated.
Conclusion
Next, I’ll analyse a more complex prompt much more rigorously.
If you are curious about mechinterp, Anthropic’s Towards Monosemanticity, Scaling Monosemanticity, and Circuit Tracing form a nice “trilogy” on this circuit tracing approach. Plus Neel Nanda’s How To Become A Mechanistic Interpretability Researcher is a good starting place more broadly.