Injecting country features in Gemma2-2b
![]()
Circuit tracing lets us identify interpretable features in language models. But if we find a feature relating to some concept, does it activate on all prompts involving that concept? And do prompts involving different concepts use analogous features in the same role?
In this post, I identify country-specific features that consistently activate when a model is prompted about cities in a given country. I then test whether these features are interchangeable by injecting the feature for one country into a prompt about another.
If we ask Gemma2-2b to predict the currency of Manchester, but amplify the India feature while negating the UK feature, it answers Indian Rupee!
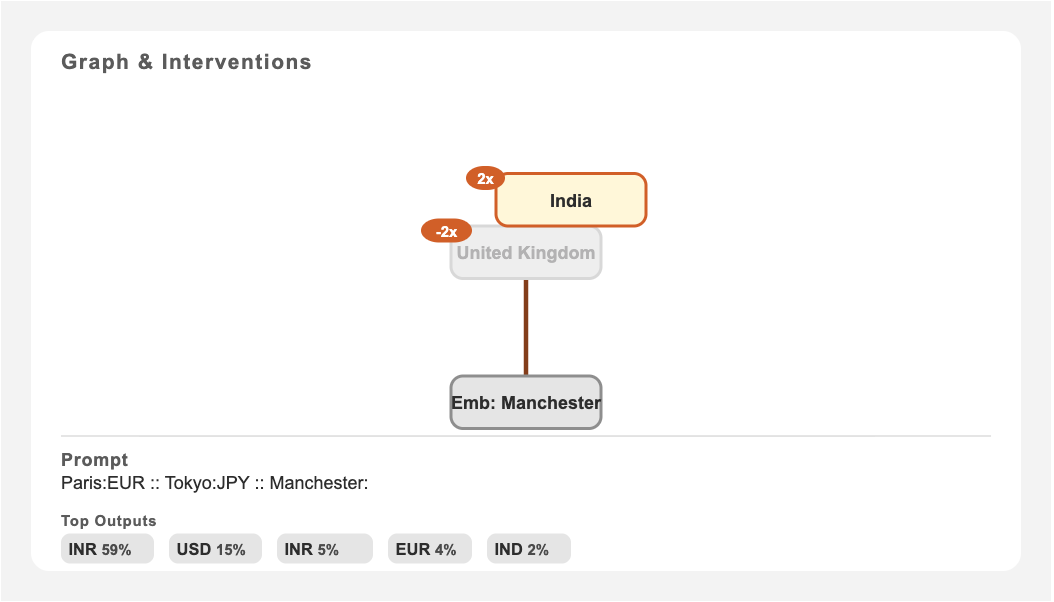
To see the full experiment, read on.
The tools
For this experiment, I used the circuit-tracer library in a Google Colab notebook, with a T4 GPU. You can follow along with my notebook here.
I also used the Circuit Tracer in Neuronpedia to manually identify features.
The dataset
In this task, we want the model to predict the currency of the country containing a given city. I chose the following multi-shot prompt (the clear format elicits better performance):
prompt_template = "Paris:EUR :: Tokyo:JPY :: {city}:"
The model is generally quite good at this task and predicts the correct ticker for a range of cities.
To be confident that the feature injection experiment would work, I chose India and the United Kingdom, two well-represented countries that the model likely has strong, distinct features for. I listed six cities for each country:
# Define dataset
countries = {
"India": {
"ticker": "INR",
"cities": ["Mumbai", "Delhi", "Chennai", "Kolkata", "Bangalore", "Hyderabad"],
},
"United Kingdom": {
"ticker": "GBP",
"cities": ["London", "Manchester", "Birmingham", "Edinburgh", "Liverpool", "Bristol"],
},
}
It is important to verify that the model can actually do this task; that its highest confidence prediction for each city is the correct ticker:
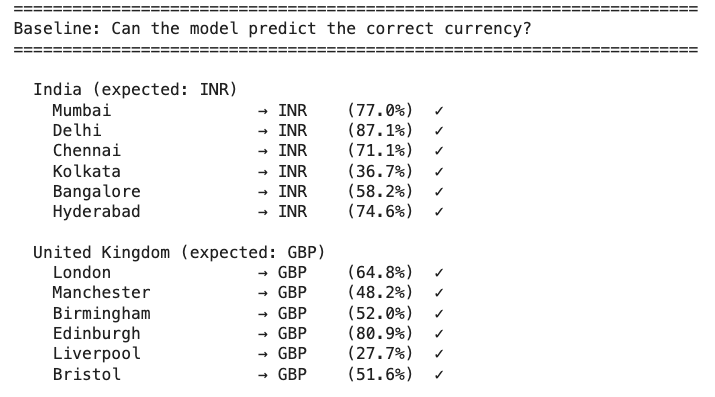
As expected, the model robustly predicts the correct token. This is impressive for a small model, and may suggest that it is doing something more sophisticated than just memorising every possible city/currency pair.
The country features
This experiment assumes that the model has features representing individual countries, and that these are somehow used to output the correct answer. If we can find these features and ablate them, the model should output the wrong currency. In my previous post, I identified these features for a different country, so I was confident more would exist.
To find these features, I simply generated attribution graphs for a city in each country (Manchester and Mumbai) on Neuronpedia. Then I manually noted down any features with the name of the country in their automated label, focusing on the later layers of the final token position.
For example, the features for India (in black) can be seen here in the top-right:
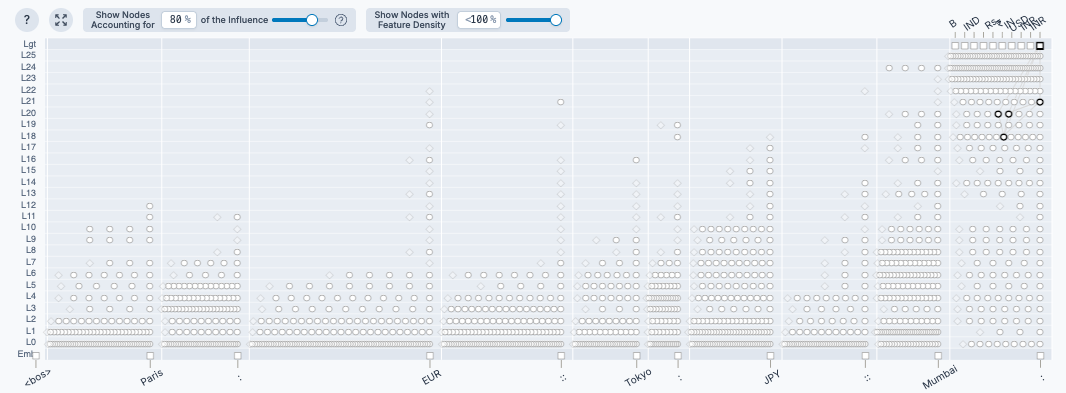
This surfaced 4 features for India and 3 for the UK.
# Define features
india_features = [
Feature(layer=20, pos=None, feature_idx=9559), # Indian
Feature(layer=21, pos=None, feature_idx=607), # India-related business texts
Feature(layer=20, pos=None, feature_idx=8828), # India
Feature(layer=18, pos=None, feature_idx=12013), # India
]
uk_features = [
Feature(layer=20, pos=None, feature_idx=3744), # UK
Feature(layer=18, pos=None, feature_idx=10922), # England/Britain
Feature(layer=23, pos=None, feature_idx=5510), # United Kingdom / United States
]
Then, I verified that these candidate features only activated on the cities of that country:
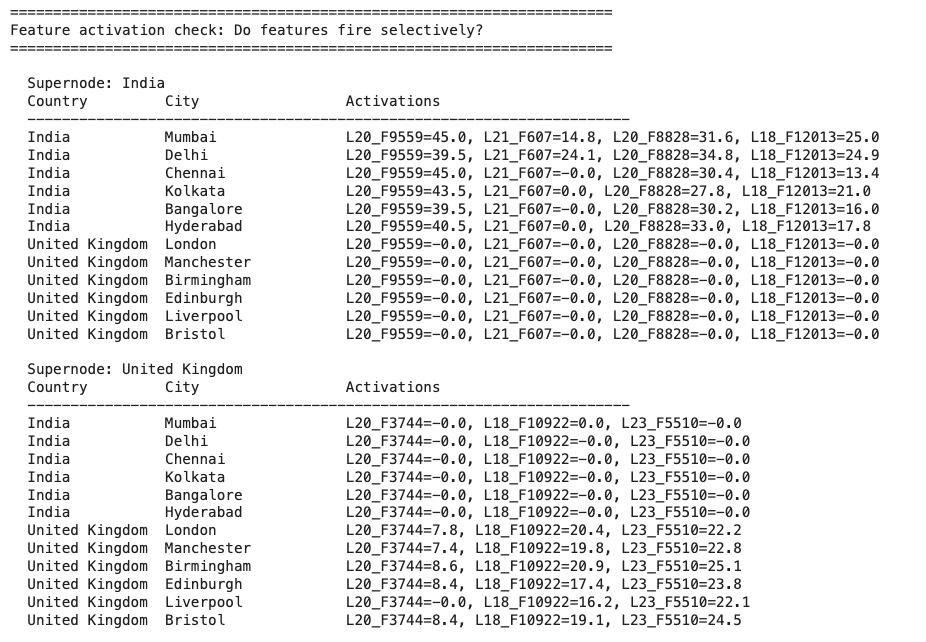
As expected, the supernode for a given country activates strongly when the model is asked about that country, but has zero activation when asked about others.
Similarly, I tested that negating each supernode “breaks” the model’s output on cities in that country.
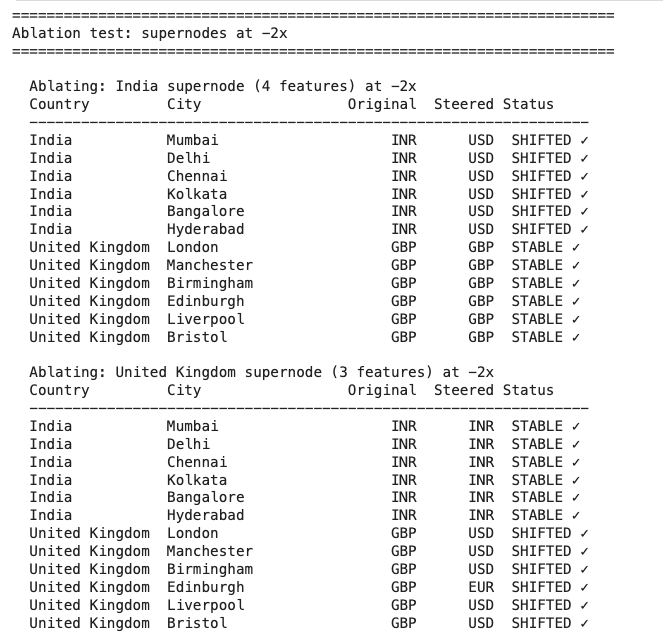
When each country’s supernode is negated, the model instead answers USD (or EUR) for that country!
These features clearly play a role. In general, it is promising that the model appears to have analogous representations of individual countries in the final layers.
Feature injection
We can now attempt to “inject” the activations for one country’s features into the prompt for the other. If these two supernodes do indeed serve the same role in this currency circuit, but for different countries, then we can use them interchangeably.
Of course, the India supernode does not naturally activate on UK prompts. To address this, we first run a prompt for an Indian city, e.g. Mumbai and capture all the activations from that forward pass. Then we can extract the India supernode activations specifically and inject them into other prompts.
# Run the Mumbai prompt to capture India feature activations
source_prompt = "Paris:EUR :: Tokyo:JPY :: Mumbai:"
_, source_activations = model.get_activations(source_prompt)
# Run the Manchester prompt to capture UK feature activations
prompt = "Paris:EUR :: Tokyo:JPY :: Manchester:"
logits, activations = model.get_activations(prompt)
# Build the UK node from the Manchester prompt (naturally active)
uk_node = Supernode(name="United Kingdom", features=uk_features)
graph.initialize_node(uk_node, activations)
# Build the India node using activations sourced from Mumbai
india_node = Supernode(name="India", features=india_features)
india_source = Supernode(name="India_source", features=india_features)
source_graph.initialize_node(india_source, source_activations)
india_node.default_activations = india_source.default_activations
# Intervene: suppress UK, amplify India
supernode_intervention(graph, [Intervention(uk_node, -2), Intervention(india_node, 2)])
We can visualise this for a specific prompt. First, without any interventions, the Manchester embedding activates the United Kingdom supernode, and the model predicts GBP:

However, if we negate the United Kingdom supernode and inject the India supernode, the model predicts INR:
Note that we use a scaling factor of -2x rather than simply zeroing out the UK features. In theory, 0x would remove the UK signal, but I found this produced cleaner results than just ablating in practice.
With this procedure established, we can inject “India” into all the UK prompts and vice versa:
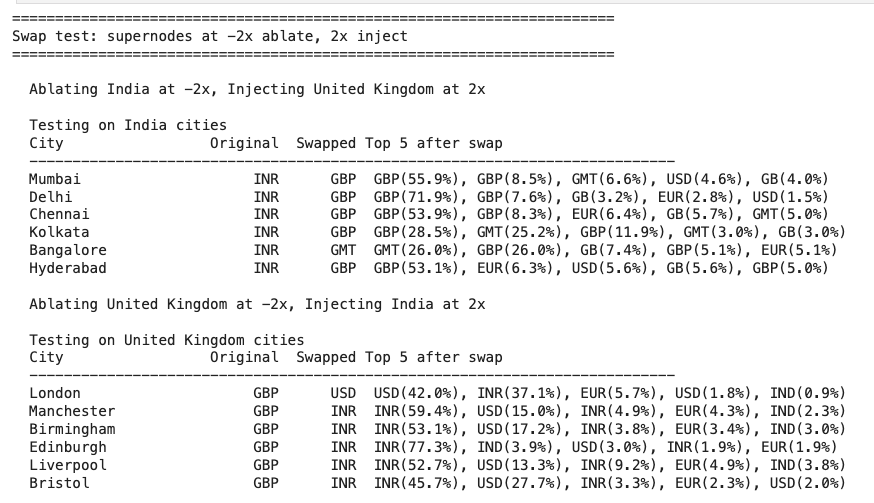
As hoped, the model predictions completely changed - GBP became the top prediction for Indian cities and INR for the United Kingdom! In addition, each country’s own currency is completely absent from its predictions due to the negative steering.
Conclusion
This experiment provides a neat interpretability result. Not only does the model have distinct features for particular countries, but they are actually used interchangeably.
To expand on this experiment, I would test it on more countries. My initial tests showed that injection did not work on less well-represented countries - it is possible that the features do not exist or the computation is more distributed.
In addition, I would like to try automatically discovering features by comparing their activations on various inputs. I am also keen to establish a rigorous “end to end” understanding of this currency circuit or another format of prompt, beyond looking at single features.